Foundation Time-Series Model Research Agenda
Visual Map
Collaboration
If this direction resonates with you, I would be happy to talk with like-minded people, collaborate on research, and work on use-cases together.
Ideas are not the bottleneck. Hands are. Time-series modeling should be moving at least as fast as vision, audio, and robotics.
- Email: alexander.chemeris@gmail.com
- X: @chemeris
- Telegram: @alexanderchemeris
Summary
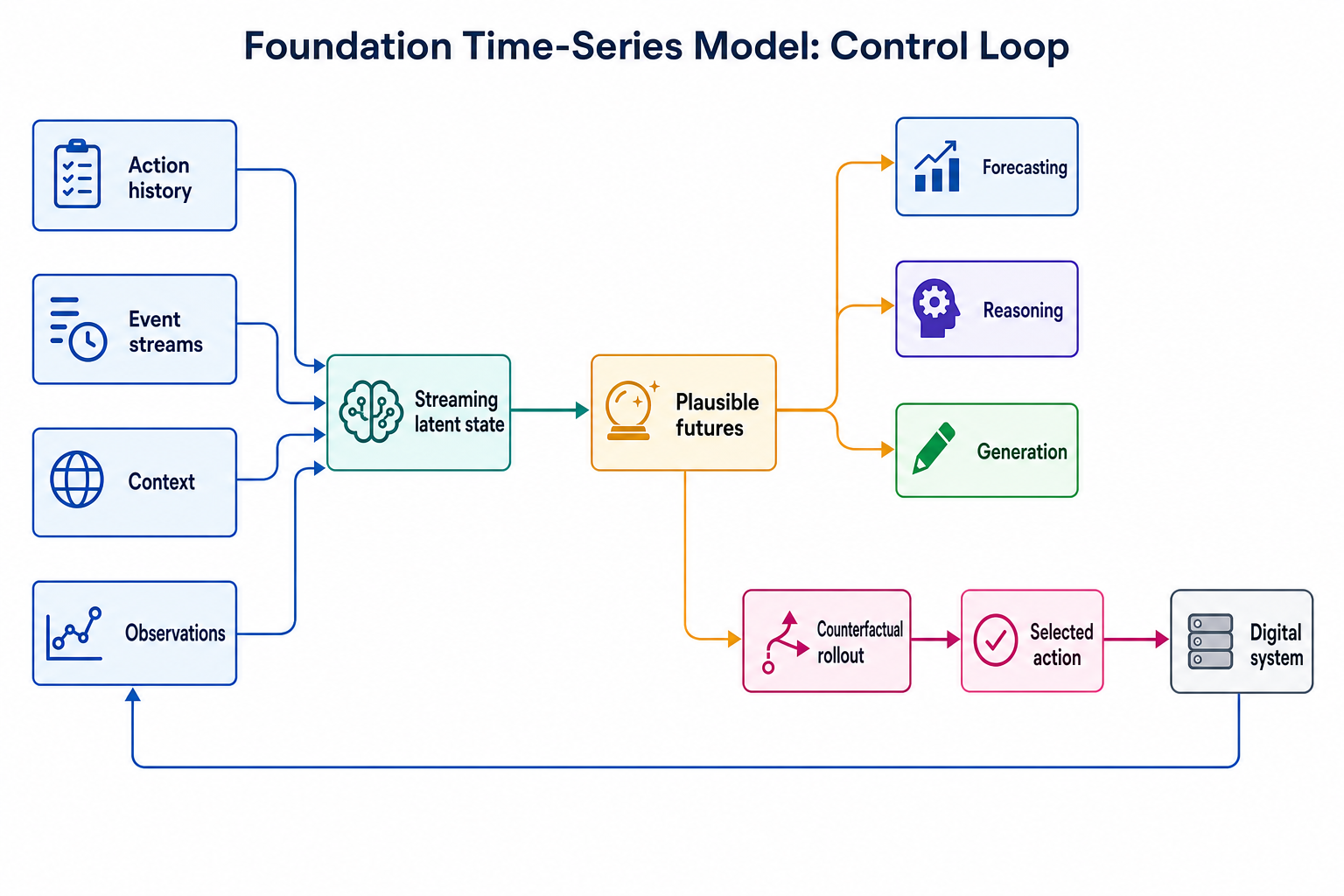
A real foundation time-series model is not just a larger forecaster. It should operate on always-on streams, maintain latent state under continuous updates, use context, handle multivariate and irregular data, preserve enough dense numeric detail for generation and editing, represent multiple plausible futures, and eventually support actions, control inputs, interventions, and counterfactual prediction.
The working test for every source in this area is simple:
Does this source close one of the bottlenecks that blocks
a general latent-state time-series model, or is it only a local
forecasting/classification/generation improvement?This page is the central organizing frame for the wiki’s time-series foundation-model work. It defines the slots into which source pages, topic pages, entities, and durable ideas should be mapped.
What’s Wrong With The Current Time-Series Deep Learning? remains the landmark position source for why observation forecasting is too narrow and why latent-state modeling matters. It answers a narrower recurring question inside this broader agenda.
Practical North Star: Digital-World Robots
The practical target is to build digital-world robots: agents for digital, organizational, and cyber-physical systems that can observe, remember, simulate, and act. A foundation time-series model is not the whole robot. It is the state and dynamics layer underneath the agent.
The robotics analogy is intentional but bounded. A physical robot has sensors, embodiment, control inputs, and a world model. A digital-world robot has telemetry, logs, traces, business events, topology, calendars, customer or user context, configuration, deployment machinery, safety constraints, and typed intervention capabilities. Its “body” is the system it can observe and affect.
This is not limited to SRE or telecom. Those are the current focus because they provide dense time-series streams, explicit system structure, and relatively clear intervention surfaces. The same frame should eventually cover digital marketing, sales operations, supply chains, finance, industrial systems, and safety-critical infrastructure such as nuclear power plants. The common requirement is a model that can represent system state, evaluate plausible futures, and reason about action consequences.
The digital-world frame is broader than observability alone. CWM is the current code-domain precedent: it treats Python execution and agentic repository work as action-observation trajectories. That is useful evidence for the data contract, but it remains outside numeric time-series modeling because its observations are program states, files, command output, and tests rather than telemetry streams.
Agentic World Modeling makes the broader taxonomy explicit: digital world models operate under software laws such as API contracts, UI state machines, file-system logic, permissions, and error branches. That is directly relevant to digital-world robots, but it also sharpens the missing piece for this agenda: SRE and operations need the same action-conditioned simulator contract over numeric telemetry, graph time series, event streams, and typed interventions.
World Model for Robot Learning Survey adds the robotics-specific boundary: for embodied agents, visual future prediction is not enough unless the predicted futures remain action-sensitive, physically executable, and useful for policy evaluation or planning. The TSFM translation is that intervention-conditioned rollouts should be judged by downstream decision utility, not only by passive forecast error.
On Training in Imagination adds a data-economics boundary for that same interface: the transition model and the reward or outcome model can have different sample costs, scaling exponents, and noise/bias profiles. For digital-world robots, the analogous split is telemetry/action-transition data versus human, SLO, or expert reward labels.
In agenda terms, the foundation time-series model supports this interface:
observations + context + action history
-> latent state
-> plausible futures under candidate interventions
-> selected action or control inputThat is why this agenda tracks streaming state, context, multi-modal future distributions, native multivariate encoding, event streams, causality, counterfactuals, dynamic compute, and benchmarks. Each slot is a missing capability on the path from passive time-series modeling to action-conditioned digital-world agents.
Existing local anchors:
- Observability Time Series covers the closest SRE/telemetry testbed.
- World Models provides the general state, future, and action-consequence frame.
- Digital World Models covers the software-defined branch of action-conditioned simulators.
- Slow Thinking For Robotics And Time Series connects physical robotics, telecom, and operational time-series systems through layered state/action interfaces.
Capability Target
The target model should expose at least these capability surfaces:
| Capability | Required Interface | Why It Matters |
|---|---|---|
| Forecasting and imputation | history, context -> future observation distribution | Basic utility, but not enough for system understanding. |
| Classification and anomaly detection | history, context -> labels, regimes, events | Tests whether representations preserve discriminative state. |
| Reasoning and question answering | history, context, query -> answer or explanation | Needed for human-facing analysis and incident understanding. |
| Generation | conditions -> plausible time-series samples | Requires calibrated distribution modeling, not only point forecasts. |
| Modification and editing | history, edit instruction -> modified series | Requires preserving original dense detail while changing selected factors. |
| Control | latent state, context, candidate actions -> future trajectory distribution | The central world-model target: choose actions by evaluating consequences. |
The capability target immediately creates a representation tension. A purely semantic embedding may be excellent for labels or decisions, but too lossy for generation and editing. A purely dense reconstruction embedding may preserve values while failing to capture regimes, causal variables, or action-relevant state. The research agenda is to make that tradeoff controllable rather than accidental.
Learning is Forgetting gives a useful adjacent language-model frame: better representations can be understood as lossy compression of objective-relevant information. For this agenda, the open question is which objective makes a time-series model compress toward action-relevant latent state rather than only average next-observation prediction.
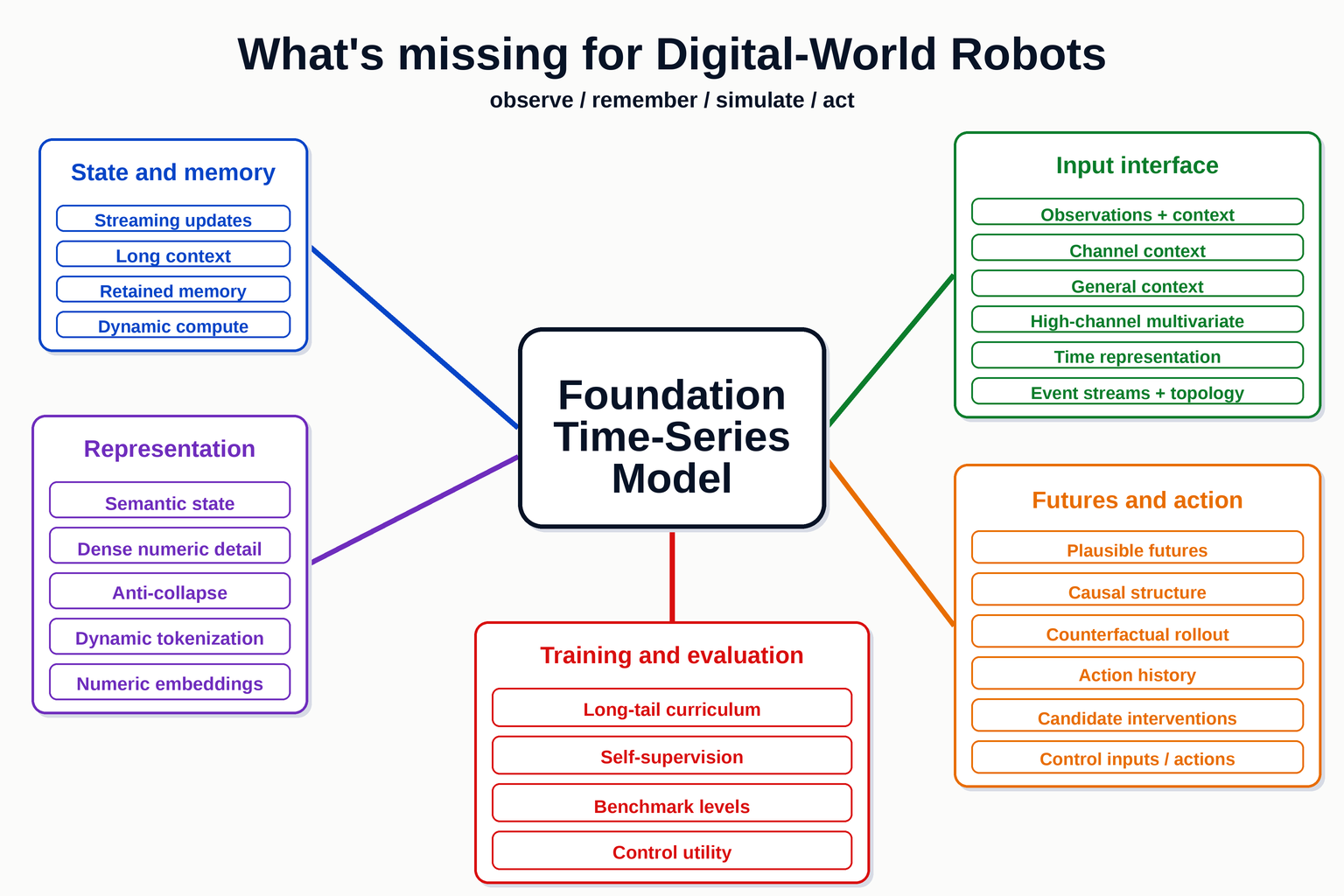
Problem Map
1. Streaming State, Long Context, And Constant Updates
Real systems produce data continuously. The context is not just long; operationally it is unbounded, with a finite retained window and new observations arriving all the time. A useful model must update state at least as fast as real time, avoid recomputing the full history after every sample, and preserve the information needed for future decisions.
Relevant existing pages:
- Latent-State Time-Series Modeling
- Time-Series Scaling And Efficiency
- Efficient Recurrent Sequence Models
- Observability Time Series
Useful evidence so far: recurrent or compact-state backbones, contiguous patch masking, efficient decoding, state-space models, rank compression, and sleep-time consolidation all help with parts of the problem. They do not by themselves prove always-on latent-state maintenance.
Language Models Need Sleep is the clearest current analogy for infinite-context streaming: an SSM-attention hybrid spends extra compute before a finite attention window is evicted, writes a better fast-weight state, then continues with cheap wake-time prediction. The TSFM version would be a learned state-refresh step over recent numeric observations, events, context, and action history before raw samples leave the retained window.
FADE adds a parameter-level continual-learning analogy: memory horizons can be adapted rather than fixed globally. That is not yet TSFM evidence, but it sharpens the requirement that online systems need selective forgetting of stale mappings while retaining stable dynamics and rare safety-relevant state.
TurboQuant adds a serving-memory warning for this slot: retained-state compression must beat hardware-native baselines after dequantization, latency, throughput, and memory-pressure regimes are counted, not only reduce bytes.
Wiki gap: create a dedicated page for streaming latent-state updates, online inference cost, retained memory, state refresh, and real-time serving contracts.
2. Multi-Modal Future Distributions
This agenda uses multi-modal here in the probability-distribution sense, not the data-modality sense. Many real systems have several plausible futures. A model that averages incompatible futures can be numerically smooth and operationally wrong.
This matters for forecasting, generation, modification, and control. A control system needs to know not only the expected future, but also which future regimes are plausible under uncertainty and which actions change the probability mass.
Relevant existing pages:
Useful evidence so far: probabilistic forecast heads, flow matching, diffusion-style generation, energy-based framing, and latent-variable world models are all partial routes. World Models is the historical action-conditioned example: an MDN-RNN models a distribution over the next latent state, and temperature exposes the tradeoff between exploitable deterministic dreams and overly noisy imagined environments. The missing test is whether the model preserves multiple decision-relevant future states rather than only calibrated marginal forecasts.
ELF adds a cross-modality substrate analogy rather than direct evidence for this slot: text generation can stay in a continuous embedding-space flow and decode to tokens only at the final step. It remains adjacent until a TSFM demonstrates multiple calibrated numeric future modes under text/context conditioning and downstream utility.
3. Data Diversity, Curriculum, And Long Tail
Real time-series corpora are useful-signal-poor. Normal operation dominates, while failures, regime changes, interventions, tail users, rare devices, unusual weather, unusual demand, and edge-case patient states are sparse.
Dynamic Curriculum Learning For JEPA frames the local idea: use model surprise to spend training compute on windows that still carry learning signal. Distribution Priors In Self-Supervised Learning adds the caution: anti-collapse losses and batch construction can impose hidden distribution priors that are harmful under long-tailed data.
Research should be scored by whether it improves rare-state preservation, not just average loss. A method that accelerates training on common patterns but erases rare regimes moves away from the foundation-model target.
The internal discussion behind the dynamic-curriculum idea sharpens this slot. The problem is not only that real corpora are noisy; it is that normal operation can dominate so heavily that the model learns to treat failures, regime shifts, and corner cases as ignorable noise. The research agenda should therefore split the work into two questions: dataset-level curriculum over unlabeled useful-signal-poor corpora, and model-level robustness so the encoder does not discard rare correlated events when the data distribution is unknown.
The publishable test is matched-compute, not just “more filtering.” A useful result should report rare-event or rare-state metrics, normal-behavior retention, corrupt-window robustness, and whether the same surprise policy transfers between multivariate time series and image/video trajectories.
4. Augmentation-Free Or Dataset-Aware Self-Supervision
Time-series augmentations are not universal. Jitter, cropping, scaling, warping, masking, permutation, and frequency transforms can be valid for one domain and destructive for another. A foundation model trained across many datasets cannot assume one augmentation family is always label-preserving or state-preserving.
This creates two routes:
- build a large library of dataset-aware augmentations and metadata rules;
- prefer objectives that need fewer handcrafted augmentations, such as latent prediction, masked modeling with careful grounding, next-state prediction, or world-model objectives.
Self-Supervised Representation Learning, JEPA, and Latent-Space Predictive Learning are the current anchors. A source helps this problem when it reduces dependence on brittle augmentation assumptions while preserving state variables and dense numeric detail.
5. Context Interface: Channel Context And General Context
Context has two separate roles.
Channel context describes what each channel means: metric name, unit, sensor type, topology node, service, region, product, physiological variable, protocol layer, or actuator. Without it, a multivariate model can see numbers but not know what the numbers are.
General context describes the system and situation: season, holiday, maintenance window, deployment, weather, user segment, market condition, topology, known incident, experiment setting, or operating mode.
Context is Key is the clean benchmark anchor for text-conditioned forecasting, while CHARM is the local source for channel-description-conditioned multivariate representations. These are partial answers: they show that context can matter, but they do not yet provide a full context interface for high-dimensional streaming systems with actions and event streams.
Research should be scored by which context type it handles and whether context is actually necessary for the target, not merely decorative metadata.
6. Representation Quality: Semantic State Vs Dense Numeric Detail
The model needs semantic state for regimes, events, causal variables, and decisions. It also needs dense numeric detail for high-fidelity forecasting, generation, imputation, and modification.
EIDOS is the local time-series anchor because it predicts latent representations while grounding them back to observations through a reconstruction head. Reconstruction Or Semantics? shows the robotics version of the same conflict: semantic latents can be more policy-relevant than reconstruction latents, but dense fidelity still matters for geometry and contact.
The unresolved target is inference-time control over what information is preserved. A model should not use one fixed representation policy for every query. Forecasting a smooth seasonal signal, editing a spike, detecting an incident, and choosing an intervention may require different layers, heads, or latent subspaces.
Research directions to track:
- auxiliary losses that keep dense numeric information available in deeper layers;
- intermediate-layer access rather than only final-layer representations;
- depth-wise attention or attention-residual mechanisms that let later layers retrieve earlier representations;
- task-conditioned readout from semantic and dense states;
- probes that test reconstruction, generation, modification, and decision relevance separately.
The local JEPA-curriculum notes add a concrete NEPA-style warning for this slot: in a next-embedding-prediction time-series setup, moving the target from patch-independent embeddings to contextual or internal-layer representations made latent prediction worse when those targets appeared to mix away local differences.
7. Anti-Collapse Regularization
Avoiding constant collapse is necessary but not sufficient. A representation can be non-collapsed and still learn the wrong factors, such as slow distractors, common regimes, or nuisance variables.
Representation Collapse tracks this cluster. JEPA Slow Features is the warning source, while LeJEPA, When Does LeJEPA Learn a World Model?, and LeWorldModel anchor Gaussian or distribution-regularized JEPA-style approaches. The identifiability result is especially useful because it distinguishes a non-collapsed embedding from a linearly usable latent state under stated Gaussian/OU assumptions. The Hidden Uniform Cluster Prior adds the long-tail warning: the anti-collapse prior itself can bias what the model preserves.
For foundation time-series models, the key question is whether regularization preserves rare regimes, cross-channel deviations, intervention effects, and multiple plausible futures.
8. Patch Size, Dynamic Tokenization, And Point-Wise Numeric Embeddings
Fixed patch size is a hidden modeling assumption. The right temporal resolution varies across datasets, across channels, and even inside one signal. A quiet hour of server metrics and a bursty incident window should not be encoded at the same density.
The agenda needs both extremes:
- adaptive patching for redundant or low-information spans;
- point-wise numeric embeddings for cases where every sample may matter.
ReinPatch and Kairos are current adaptive-tokenization anchors. EIDOS is the point-wise numeric-token anchor. Number Tokenization tracks related scalar encodings such as Fourier, bit-level, and typed numeric embeddings.
Compute Optimal Tokenization adds an upstream scaling-law constraint: if granularity changes, the unit used to state scaling laws must change too. For text, the paper argues for bytes per parameter rather than tokens per parameter. A time-series foundation model needs the analogous unit before claiming compute-optimal patching or compression, and that unit may differ for dense samples, sparse event streams, high-channel telemetry, and action logs.
A source helps this problem when it makes token granularity data-dependent without erasing change points, spikes, missingness, local causal events, or channel-specific deviations.
9. Native Multivariate Encoding And High-Channel Scaling
Multivariate time series cannot be reduced to a slogan like “embed separately” or “embed together.” Channel-independent models improve transfer and serving simplicity, but can miss cross-channel dynamics. Naive channel-dependent attention can become too expensive and noisy.
High-Dimensional Time Series Forecasting is the current topic page. U-Cast and Time-HD anchor thousand-channel passive forecasting. Toto, Toto 2.0, and BOOM anchor the observability version at grouped-query scale.
Graph Structure As Transformer Context tracks the topology-conditioned branch: when channels are nodes and edges in a known graph time series, the model should compare graph-context interfaces instead of flattening topology into anonymous channel order.
Research should be scored by:
- whether it is channel-independent, channel-dependent, factorized, hierarchical, graph-conditioned, or retrieval-based;
- whether it preserves cross-channel interactions;
- whether it scales to hundreds, thousands, or tens of thousands of channels;
- whether it handles channel metadata and topology;
- whether it stays passive or introduces actions/control inputs.
10. Time Representation And Irregular Event Streams
Regular time series can often use sample index as a proxy for time. Irregular time series and event streams cannot. The model may need elapsed time, calendar time, sampling rate, event order, duration, missingness, seasonality, and asynchronous channel updates.
T-Rep is the current source for learned time embeddings. FlowState is relevant because it uses coefficient-space and continuous basis decoding for flexible sampling rates. The broader wiki still needs a dedicated topic page for time representation across regular samples, irregular time series, event streams, continuous time, and calendar time.
Research helps this problem when it makes time a first-class input rather than an accidental positional index.
11. Dynamic Compute Allocation
Easy windows and hard windows should not receive identical computation. Dynamic compute can happen through sparse experts, recursive or looped depth, pause or thinking tokens, adaptive inner steps, hierarchical compression, or energy-based search.
Current local anchors:
- Mixture Of Experts
- Time-Series Scaling And Efficiency
- Hierarchical Modeling with a Fixed FLOPs Budget
- Energy-Based Models
- EBT
- Looped Transformers And Test-Time Memory
- MoDA
- mHC
- Hyperloop Transformers
- ELT
- Language Models Need Sleep
H-Net, ConceptMoE, and Compute Optimal Tokenization are useful architecture and scaling analogs for learned hierarchy and implicit compute allocation. EBT adds an explicit search path: score candidate predictions with an energy function, then spend more optimization steps or more candidate samples when the prediction is hard. The time-series-specific target is stronger: allocate compute to spans, channels, regimes, and candidate futures that matter for latent-state maintenance and control.
Scaling Test-Time Compute for Agentic Coding is an adjacent runtime-compression example: long action-observation traces become more useful after structured summarization, selection, and refinement. The transfer target is not raw prompt summarization of telemetry, but learned state compression that preserves action-relevant facts under a compute budget.
DiffusionBlocks adds an adjacent training-memory route: local denoising objectives can reduce full-depth backprop memory and recurrent-depth BPTT cost, but pretrained conversion, privacy, and numeric time-series state preservation remain untested.
Recurrent Transformer depth, depth-state retrieval, residual-stream capacity, loop-boundary supervision, and energy-based optimization loops belong here as adjacent dynamic-compute mechanisms, not as automatic progress on the curriculum slot. Universal Transformers, Huginn, Latent Thoughts, MoDA, mHC, Hyperloop Transformers, ELT, LoopFormer, Parcae, and Sparse Looped LMs are promising for real-time deployment, early exit, uncertainty signals, depth-memory retrieval, residual-state capacity, and bounded-memory inference, but they need matched comparisons against wider or deeper unique-weight models and direct evidence that extra depth compute, depth communication, loop-boundary supervision, or residual-stream width preserves decision-relevant temporal state. Parallel Samplers and The Recurrent Transformer sharpen the serving contract: dynamic compute must be evaluated against realized throughput, key-value cache traffic, and exact decoding schedules, not only nominal FLOPs. MoDA and mHC add the same warning for inter-layer communication and residual-stream capacity: depth retrieval or matrix residual state may help only if the cache, memory bandwidth, and kernel budgets are explicit. ELT adds a useful visual-generation example where intermediate loop exits are trained directly, but TSFMs still need calibrated stopping rules and numeric-state preservation probes. Extra recurrence inside an Energy-Based Transformer is especially a design risk: the EBT inference procedure already has an iterative energy-gradient loop, so the first question is whether the energy landscape or candidate search is the bottleneck.
Language Models Need Sleep adds a consolidation-time version of this question for SSM-attention hybrids. Extra compute is spent before context eviction to write a better fast-weight state, not during every later prediction. For TSFMs, the analogous design would be an online state refresh step at window boundaries in an infinite stream, but the evidence remains language/synthetic until it is tested on numeric streams, event streams, and action histories.
Dragon Hatchling adds a stronger fast-state architecture hypothesis: make the mutable recurrent state a central part of the model, keep sparse positive activations, and probe individual state/synapse behavior. For this agenda it is important but adjacent evidence. It sharpens the streaming-state and dynamic-compute slots, while still missing numeric time-series, event-stream, and action-conditioned tests.
Titans and ATLAS add a complementary memory-at-test-time route. For this agenda, the interesting question is whether memory updates preserve rare regimes, cross-variate relationships, exogenous context, and intervention history, not only whether they improve recall-style long-context tasks.
HRM, TRM, URM, and Universal Transformers Need Memory are adjacent recursive-reasoning evidence. They are useful for latent-state refinement, supervision, memory-slot, and halting-budget design, but still puzzle evidence until tested on numeric time series, event streams, or action-conditioned trajectories.
Loop convergence itself may be useful as a diagnostic. If a recurrent block needs unusually many iterations before representations stabilize, that can act as an uncertainty or failure signal; if additional loops saturate after a small number of iterations, test-time compute has diminishing returns and should be capped.
Candidate sources to ingest later:
Think before you speak: Training Language Models With Pause Tokensfor delayed next-token prediction.Attention Residualsfor learned access over previous layer outputs.Inner Thinking Transformerfor adaptive internal depth.
These candidates should not be treated as wiki evidence until they have source pages.
12. Benchmarks: What Level Of Modeling Is Tested?
The benchmark question is not “which model has the best score?” It is “what level of modeling did the score test?”
The agenda should separate at least these levels:
| Level | Question | Failure If Missing |
|---|---|---|
| Shape forecasting | Can the model extrapolate visible morphology? | Repeats curves without understanding process state. |
| Latent-state prediction | Does it track regime, constraints, and hidden state? | Good forecast error but weak rare-event and decision behavior. |
| Context use | Does context change the predicted distribution correctly? | Numeric history is treated as complete when it is not. |
| Multi-modal futures | Does it preserve multiple plausible futures? | Averages incompatible outcomes. |
| Causal/counterfactual reasoning | Does it represent intervention consequences? | Confuses passive events with actions. |
| Control utility | Does it choose or rank better actions? | Forecasts well but cannot act. |
Time-Series Benchmark Hygiene is the current page. Future benchmarks should report whether they test observation forecasting, state prediction, context sensitivity, rare-regime preservation, high-dimensional channel interaction, irregular/event-stream handling, generation fidelity, modification fidelity, or action-conditioned rollout.
13. Causal Structure, Counterfactuals, And Control
A foundation time-series model should eventually support counterfactual prediction: what would happen under a different action, control input, or intervention? This is distinct from conditioning on exogenous future events.
Causal Time Series is currently small. CauKer uses causal structure for synthetic time-series generation, while TimeOmni-1 includes causal discovery as a reasoning target. Action-Conditioned Time-Series Datasets tracks the dataset side.
The world-model test is whether the model can evaluate future trajectories under candidate actions. Passive forecasting, even when probabilistic and high-dimensional, does not close this problem.
Source Assessment Rubric
Every new paper, dataset, model, or benchmark in this agenda should be evaluated with the same rubric.
| Field | Question |
|---|---|
| Problem block | Which bottleneck above does it address? |
| Interface | What are the inputs and outputs? History only, context, channel metadata, event stream, action, control input, intervention, query, edit instruction? |
| Data regime | Regular or irregular, univariate or multivariate, low-channel or high-dimensional, single-domain or diverse, balanced or long-tailed? |
| Evidence type | Model result, benchmark, dataset, theory, position paper, ablation, or architecture analogy? |
| Capability surface | Forecasting, imputation, classification, reasoning, generation, modification, control, or evaluation hygiene? |
| Slot-level verdict | For each agenda slot: closes, partially closes, adjacent, warning, or insufficient evidence. |
| Missing pieces | What must be added before it supports a foundation time-series model? |
Use this verdict vocabulary consistently:
- Closes: directly solves a required interface or evaluation gap with convincing evidence.
- Partially closes: solves a narrow version, usually passive, low-dimensional, single-task, or missing actions/context.
- Adjacent: useful mechanism or analogy from another domain.
- Warning: exposes a failure mode, bias, or benchmark caveat.
- Insufficient evidence: uses nearby language or improves a local score without enough evidence to count as progress on the agenda slot.
Verdicts are per slot, not per source. If one paper helps context conditioning
but says nothing about control, the context row can be partially closes while
the control row is insufficient evidence. If another paper is mainly valuable
because it shows a benchmark or representation failure, the affected slot should
be marked warning rather than merged into a generic source-level verdict.
Current Research Coverage Matrix
This matrix is intentionally selective. It lists only landmark or important
source pages, or tight source clusters, that have at least one closes or
partially closes slot-level verdict. Pure warnings, adjacent analogies,
diagnostics, normal-priority sources, and insufficient-evidence entries belong
on the relevant source and topic pages, not in this central agenda table.
| Source | Slot-Level Signals | Missing For Foundation TSFM |
|---|---|---|
| What’s Wrong With The Current Time-Series Deep Learning? | Latent-state prediction: closes problem framing; benchmark level: warning; context and long tail: partially closes framing. | Needs implementation and benchmark suite. |
| Context is Key | General context: partially closes; native multivariate encoding: insufficient evidence; control/counterfactuals: insufficient evidence. | Univariate, text-only, no native multivariate state or action interface. |
| CHARM | Channel context: partially closes; native multivariate encoding: partially closes; control/counterfactuals: insufficient evidence. | Channel-time attention cost and passive task surface. |
| EIDOS | Latent prediction: partially closes; dense numeric detail: partially closes; point-wise numeric embeddings: partially closes; control/counterfactuals: insufficient evidence. | Univariate-first passive forecasting; no action/control interface. |
| Scaling-laws for Large Time-series Models and Scaling Law for Time Series Forecasting | Scaling substrate: partially closes; data diversity: partially closes; benchmark horizon choice: warning. | Passive forecasting evidence; no native multivariate, context-rich, or action-conditioned scaling laws. |
| Mamba-2 | Streaming state and efficiency: partially closes; native multivariate encoding: insufficient evidence. | Sequence-model evidence is language/retrieval centered; needs always-on numeric state benchmarks. |
| Dragon Hatchling | Streaming fast state and interpretability: adjacent; dynamic sparse updates: adjacent. | Language/translation preprint; no numeric time-series, event-stream, action, control-input, or intervention evidence. |
| RATE | Streaming state for action trajectories: partially closes; control and counterfactuals: adjacent. | Offline RL policy model over return-conditioned trajectories; no learned next-state simulator, telemetry serving state, or candidate-intervention rollout. |
| World Models | Control/counterfactuals: partially closes outside time series; multi-modal future distributions: partially closes via MDN-RNN latent mixtures; benchmark level: warning. | Visual Gym tasks, staged VAE + MDN-RNN + CMA-ES stack, no operational telemetry, typed digital interventions, context schema, or modern scaling. |
| World Model for Robot Learning Survey | Context interface: partially closes outside TSFM; benchmarks: warning; causal/control utility: adjacent. | Survey evidence, mostly visual robotics; no numeric telemetry, typed digital interventions, or unified TSFM benchmark. |
| Genie | Control/counterfactuals: partially closes outside time series; data diversity and scaling substrate: partially closes outside time series; benchmark level: warning. | Image/video trajectories with learned latent actions; no numeric telemetry, typed action logs, intervention outcomes, long-horizon consistency, or real-time control. |
| FoNE | Point-wise numeric embeddings: partially closes; arithmetic benchmark level: warning. | Not yet tested on units, noisy continuous sensors, missingness, forecasting, or control inputs. |
| LeJEPA, LeJEPA Identifiability, and LeWorldModel | Anti-collapse regularization: partially closes outside time series; state identifiability: adjacent outside time series; world-model stability: partially closes outside time series. | Strong for vision/control and Gaussian-latent theory, not yet time-series foundation evidence; action-conditioned identifiability remains open. |
| U-Cast, Time-HD, and BOOM | High-dimensional multivariate forecasting: partially closes; observability benchmark coverage: partially closes; control/counterfactuals: insufficient evidence. | Passive benchmarks; no event streams or interventions. |
| Toto 2.0 TSALM Workshop Presentation | Observability context roadmap: partially closes; incident-response benchmark level: partially closes; control/counterfactuals: insufficient evidence. | Talk-level and internal-benchmark evidence; no released action-conditioned observability model. |
| FlowState | Time representation: partially closes; sampling-rate invariance: partially closes. | Needs unified regular/irregular/event-stream time interface. |
| CauKer and TimeOmni-1 | Causal structure: partially closes; counterfactual action-conditioned rollout: insufficient evidence. | Need counterfactual action-conditioned rollout evidence. |
| ChatTS | Context interface: partially closes; semantic-vs-dense numeric detail: partially closes; reasoning benchmark level: partially closes. | Synthetic-heavy QA; no operational context, actions, dense reconstruction, or calibrated future rollout. |
| TimeOmni-VL and T2S | Generation: partially closes; multimodal reasoning: partially closes; modification/editing: insufficient evidence; control utility: insufficient evidence. | Need observed-history editing, dense preservation, and control utility. |
| Scaling Test-Time Compute for Agentic Coding | Context interface: partially closes outside TSFM; dynamic compute and runtime compression: adjacent. | Agentic coding only; prompt-generated summaries; no numeric telemetry, learned streaming state, or action-conditioned future model. |
| Diffusion Policy, GR00T N1, π0.7, and RDT-1B | Multi-modal action distributions: partially closes; control interface: partially closes for physical robots; digital-world transfer: adjacent. | Robot policies, not latent world models that compare future system trajectories under candidate interventions. |
| A Path Towards Autonomous Machine Intelligence and VL-JEPA | Abstract predictive state and selective decoding: partially closes conceptually; action-conditioned rollout: adjacent to warning. | Vision/autonomous-intelligence evidence; needs numeric time-series implementation and benchmarks. |
| EBT | Dynamic compute allocation: partially closes outside time series; energy-based candidate verification: adjacent. | Text/video/image evidence only; no numeric time-series, streaming, calibrated scenario, or action-conditioned control benchmark. |
Proposed Wiki Structure
Use this page as the research-agenda hub, then keep detailed evidence in topic and source pages.
Existing pages that should stay central:
- Time-Series Foundation Models
- Latent-State Time-Series Modeling
- Context-Aided Forecasting
- High-Dimensional Time Series Forecasting
- Graph Structure As Transformer Context
- Number Tokenization
- Distribution Priors In Self-Supervised Learning
- Representation Collapse
- Latent-Space Predictive Learning
- Time-Series Scaling And Efficiency
- Time-Series Benchmark Hygiene
- Training Dynamics
- Causal Time Series
- World Models
- Action-Conditioned Time-Series Datasets
New pages likely worth creating:
streaming-latent-state-updates.md: long context, online updates, retained memory, real-time inference, state refresh.time-representation-and-event-streams.md: sample index, elapsed time, calendar time, continuous time, irregular time series, event streams.dynamic-compute-for-time-series.md: pause tokens, recursive depth, MoE, adaptive inner thinking, fixed-FLOPs hierarchy, energy-based search.time-series-generation-and-modification.md: generation, imputation, editing, reconstruction requirements, dense detail preservation.plausible-futures-and-calibration.md: multi-modal future distributions, uncertainty, scenario trees, probabilistic and energy-based representations.foundation-tsfm-evaluation-rubric.md: the source assessment rubric above as a reusable checklist if it outgrows this page.
Open Questions
- What is the minimal benchmark that tests always-on streaming state updates instead of static windows?
- How should a model expose multiple plausible futures in a way that is useful for action selection?
- Can one representation preserve semantic state and dense numeric detail, or do we need task-conditioned access to multiple layers or latent streams?
- What is the right context schema for channel identity, global context, topology, event streams, and actions?
- Can dynamic patching and point-wise numeric embeddings coexist in one model without brittle routing?
- When should a streaming TSFM spend compute on state consolidation before window eviction rather than on larger memory, retrieval, prediction-time loops, or wider recurrent state?
- When does native multivariate modeling justify its compute cost over channel-independent modeling?
- What time representation unifies regular samples, irregular observations, event streams, continuous time, and calendar time?
- Which dynamic-compute mechanism is easiest to make reliable under real-time serving constraints?
- What source would be strong enough to show control, not only forecasting: logged actions, interventions, counterfactuals, or an interactive gym?
- How should every future wiki source page state whether it moves the system closer to a foundation time-series model?