Kubernetes OTEL Control Minimal Demo
Status: draft demo plan for the first narrow proof of Kubernetes OTEL Control Gym.
Collaboration
If this direction resonates with you, I would be happy to talk with like-minded people, collaborate on research, and work on use-cases together.
Ideas are not the bottleneck. Hands are. Time-series modeling should be moving at least as fast as vision, audio, and robotics.
- Email: alexander.chemeris@gmail.com
- X: @chemeris
- Telegram: @alexanderchemeris
Purpose
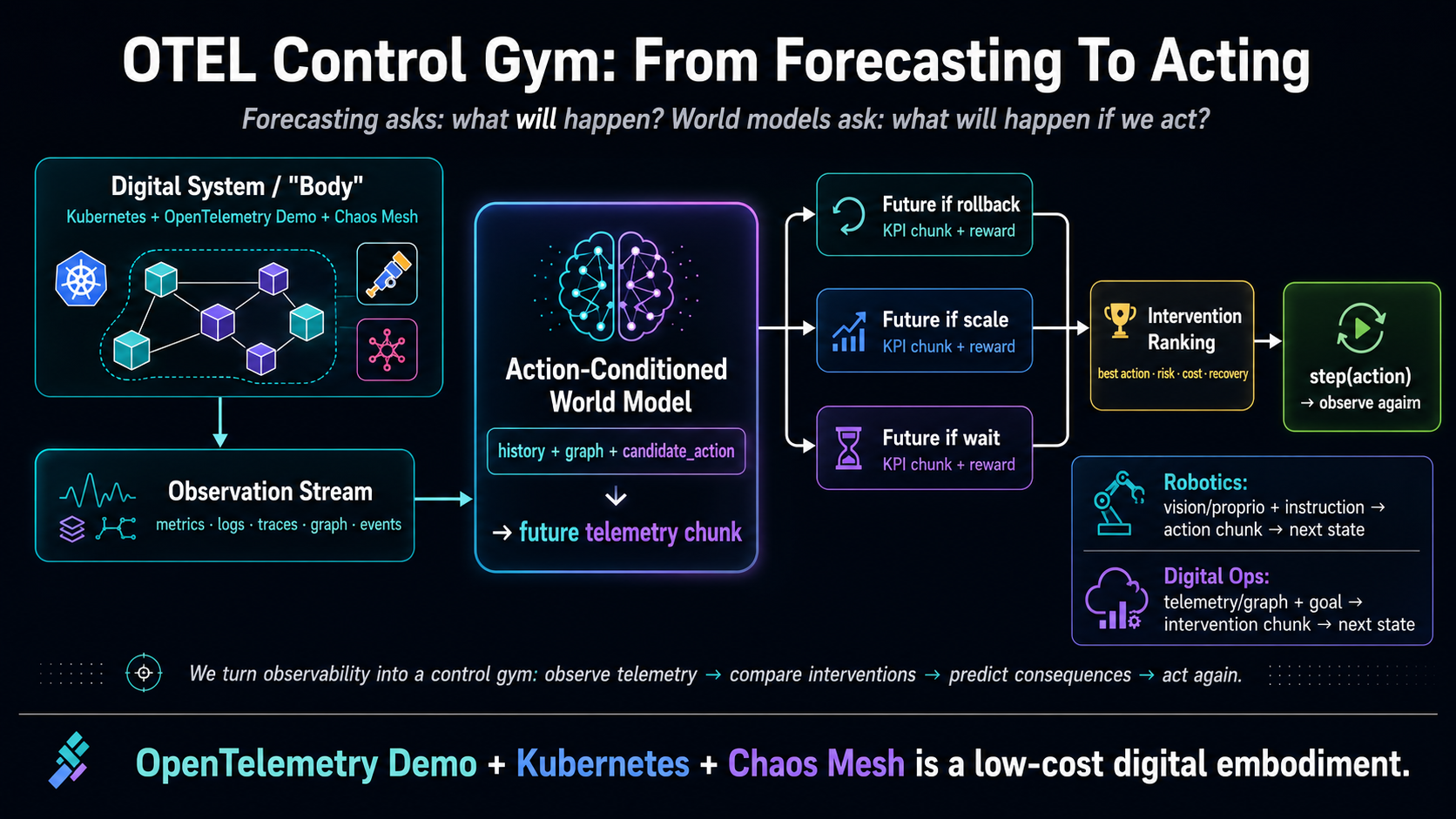
The Kubernetes OTEL minimal demo is the first working slice of Kubernetes OTEL Control Gym. The gym is the environment, data contract, and evaluation loop. The demo is the first model and user-facing proof that the loop produces useful action-conditioned trajectories.
The demo should not be presented as another passive time-series forecasting benchmark. It should be presented as:
an action-conditioned world model for digital operationsThe core question is:
What will happen if we act?not only:
What will happen if nothing changes?Robotics Analogy
In robotics, a policy loop has the shape:
robot body or simulator
-> observation
-> action chunk
-> next observation
-> rewardFor digital operations, Kubernetes OTEL Control Gym should expose the same control shape:
Kubernetes microservice stand
-> OTel / Coroot telemetry
-> DevOps intervention
-> next telemetry state
-> SLO / cost / recovery rewardIn this framing, OpenTelemetry Demo plus Kubernetes plus Chaos Mesh is a low-cost digital embodiment. A service graph is the body. Telemetry is the sensor stream. Kubernetes and Chaos Mesh actions are the actuator interface.
Minimal Demo Contract
The model-facing contract should be:
observation_history + graph + candidate_action
-> predicted future telemetry chunk
-> predicted reward / recovery score
-> action rankingThe gym-facing contract remains:
reset(seed, config) -> initial_observation
observe(window, granularity) -> observation
step(action, dt) -> observation, reward, done, infoThe demo is successful only if the model can compare candidate actions, not merely forecast one observed continuation.
MVP Scope
Keep the first Kubernetes/OpenTelemetry slice smaller than the full Kubernetes OTEL Control Gym MVP. The goal is end-to-end correctness, not production realism.
Application:
- OpenTelemetry Demo
small-core. - Metrics-first telemetry.
- Static service graph per run.
- Optional Kubernetes events.
- Traces and logs can be added after metrics, graph, actions, labels, and rewards are reliable.
Observations:
- service request rate;
- service error rate;
- service latency summaries;
- CPU and memory usage;
- restarts;
- edge request rate;
- edge error rate;
- edge latency summaries;
- workload rate or request mix.
Actions:
do_nothing;- scale a target service up or down;
- restart a deployment or pod;
- rollback or flip a config flag;
- change workload rate or request mix as a controlled input.
Faults and events:
- traffic spike;
- CPU pressure;
- network delay on a service edge;
- pod kill or restart loop;
- bad config or degraded dependency.
Rewards:
- p95 latency SLO satisfaction;
- error-rate penalty;
- recovery time;
- resource cost;
- instability penalty;
- unsafe-action penalty.
Demo Scenario
The first public-facing scenario should be a single incident with several plausible interventions.
Incident:
checkout latency grows
cart errors increase
queue depth rises
p95 latency SLO is violated
Candidate actions:
do nothing
scale checkout +2
restart cart
rollback checkout
reduce workload or enable rate limiting
Model outputs:
future p95 latency under each action
future error rate under each action
probability of SLO recovery
expected recovery time
resource cost
Recommended action:
the action with the best reward / risk tradeoffThe UI should show future trajectories under each action side by side. The important visual is not a single forecast chart; it is a what-if comparison.
First Model
The first model should be deliberately simple.
history encoder:
last 30-60 telemetry buckets of node and edge features
graph/context encoder:
service ids, edge ids, topology embeddings, workload profile
action encoder:
action_type, target service or edge, numeric parameters
future chunk decoder:
next 10-30 telemetry buckets
reward head:
recovery probability, expected cost, expected riskThe first output interface can be deterministic or quantile-based. A later version can add a diffusion or flow head over future telemetry chunks to mirror robotics-style continuous action and trajectory generation.
Baselines
The demo should compare several baseline families. LLM Agents Need Action-Conditioned World Models frames Codex, Claude, and similar tool-calling systems as strong upper-level planner baselines rather than as opponents to dismiss.
For the code/repository reasoning layer, CWM is a relevant public baseline and precedent. It should not be counted as the telemetry-native action-conditioned model.
passive forecaster:
history -> future
LLM-agent baseline:
telemetry summary + tools + prompt -> action
action-conditioned forecaster:
history + graph + candidate_action -> future
hybrid controller:
LLM proposes candidate actions
action-conditioned world model scores them
safety policy gates executionThe passive forecaster is allowed to be strong. The point is not to win average forecast error everywhere. The point is to show that action-conditioned modeling gives better intervention ranking when actions materially change the future.
For the LLM-agent baseline, Scaling Test-Time Compute for Agentic Coding is the closest runtime-compression analogue. It suggests the baseline should test structured summaries and multi-rollout reuse, while still checking whether summaries hide telemetry fields needed for control.
The learning hypothesis is that the passive baseline must model a mixture of futures caused by unobserved operational choices, while the action-conditioned baseline sees the choice explicitly and can learn simpler conditional next-state mappings. The demo should therefore include an action-ablation check: drop, mask, or shuffle action fields and confirm that intervention ranking degrades on scenarios where actions have measurable effects.
Evaluation
The primary metric should be action quality, not only trajectory error.
Core metrics:
- future trajectory error for node and edge features;
- predicted SLO recovery accuracy;
- action-ranking accuracy against the true best action;
- action-ablation degradation when action fields are dropped, masked, or shuffled;
- regret relative to the best scripted intervention;
- safety penalty for harmful persistence when the right move is to wait, do nothing, or escalate;
- correct
WAIT,NOOP, orESCALATE_TO_HUMANrate on ambiguous or unsafe scenarios; - closed-loop reward when the model acts through
step(action, dt).
The key claim to prove:
An action-conditioned model ranks interventions better than a passive forecaster.Secondary checks:
- does the model distinguish an exogenous fault from an operator action;
- does it learn that the same action has different effects under different graph and workload states;
- does it avoid recommending actions that improve one metric while causing instability or excess cost.
The minimal demo should also preserve an MREP-style evaluation package: version-lock each scenario, save full observation/action/reward traces, record action receipts and failed-action status, classify failures by L2 boundary condition, and report tail statistics rather than only averages.
stable-worldmodel adds the evaluation caution for this demo: do not infer useful intervention ranking from trajectory error alone. Report prediction error, action-ranking quality, solver or search budget, per-step latency, distribution-shift settings, and live-stand reward as separate axes.
Record reward-label source, labeling cost, fidelity/noise assumptions, and known bias checks separately from next-state prediction error. Cheap noisy reward labels are only safe to average down when the noise is plausibly zero-mean; biased SLO or human-review labels need a separate audit.
UI
The demo UI can be small but should make the world-model claim obvious.
Current incident
p95 latency rising
error rate elevated
affected services and edges highlighted
Candidate actions
do nothing
scale checkout +2
restart cart
rollback checkout
reduce workload / rate limit
For each action
predicted p95 latency trajectory
predicted error-rate trajectory
recovery probability
expected cost
risk flag
Recommendation
best action
why this action beats the alternativesThe UI should not oversell autonomy. The first demo is a decision-support and model-evaluation surface.
Implementation Path
Level 0: synthetic simulator.
- Use a small stochastic service-graph simulator.
- Validate schema, model code, UI, and action-ranking metrics.
- Avoid Kubernetes friction while the data contract is still changing.
Level 1: real Kubernetes OTEL Control Gym MVP.
- Deploy OpenTelemetry Demo
small-core. - Add metrics-first observation export.
- Implement 3-5 actions.
- Implement 3-5 faults or controlled events.
- Run 100-200 labeled episodes.
- Train passive and action-conditioned baselines.
Level 2: robotics-style chunk model.
- Predict future telemetry chunks directly.
- Add flow or diffusion head over future numeric blocks.
- Evaluate receding-horizon prediction and re-ranking.
Level 3: closed-loop controller.
- Let the model choose actions through the gym API.
- Compare against scripted baselines.
- Report reward, recovery time, safety penalties, and intervention regret.
Acceptance Criteria
The first demo is good enough if it can show:
- a real or simulated service graph;
- time-bucketed node and edge telemetry;
- logged actions and interventions;
- next-state labels and reward;
- passive and action-conditioned baselines;
- a what-if UI for candidate actions;
- action-conditioned ranking that beats passive forecasting on scenarios where action choice matters.
It does not need to solve general SRE automation. It needs to prove the controlled loop and the modeling interface.
Pitch Framing
For a robotics and control audience, the strongest framing is:
We are testing whether robotics-style action-conditioned models transfer
from physical action chunks to digital intervention chunks.The scope boundary is:
- physical robots are not the target domain for this demo;
- digital operations are a separate control environment;
- the shared research object is the architecture pattern: observe, maintain state, compare actions, predict consequences, act again.
Useful one-liner:
OpenTelemetry Demo + Kubernetes + Chaos Mesh is our low-cost digital embodiment.Relationship To Kubernetes OTEL Control Gym
Kubernetes OTEL Control Gym is the full controlled stand for action-conditioned time-series world models in DevOps.
This page is the smallest demo that can make the idea legible:
Kubernetes OTEL Control Gym = environment + data contract + closed-loop evaluator
Kubernetes OTEL Control Minimal Demo = first model + first scenario + first what-if UIThe minimal demo should feed back into the full gym design. If the demo cannot produce clear action effects, useful labels, and meaningful rewards, the larger gym will only scale ambiguity.
Relation To Foundation TSFM Agenda
This is an idea page, so the verdicts below describe the intended contribution if the proposed system or experiment works. Evidence status is recorded separately in the Evidence and Missing pieces columns.
The demo is a concrete step toward the digital-world robot north star: it treats OpenTelemetry Demo, Kubernetes, and Chaos Mesh as a small observable and intervenable digital environment. The table below maps that contribution to agenda slots rather than treating the north star as a separate slot.
| Agenda slot | Verdict | Evidence | Missing pieces |
|---|---|---|---|
| Causal structure, counterfactuals, and control | partially closes | If implemented, the demo would compare candidate DevOps actions by predicted future telemetry, reward, recovery, and action ranking. | Produce real or simulated episodes proving that action-conditioned ranking beats passive forecasting. |
| Benchmarks: what level of modeling is tested? | partially closes | If implemented, action quality, intervention ranking, regret, and closed-loop reward become primary metrics instead of only trajectory error. | Implement baselines and report failure cases. |
| Multi-modal future distributions | adjacent | Proposes a what-if UI with side-by-side plausible futures under different candidate actions. | First model can be deterministic or quantile-based; multi-modal future modeling is deferred. |